2010년 10월 31일 일요일
내분검색
/* Written by Sanchit Karve (born2c0de)
Contact Me on born2c0de AT dreamincode DOT net
*/
#include
#include
#define MAX 5
int interpolationsearch(int a[],int low,int high,int x)
{
int mid;
while(low<=high)
{
mid=low+(high-low)*((x-a[low])/(a[high]-a[low]));
if(x==a[mid])
return mid+1;
if(x
else
low=mid+1;
}
return -1;
}
int main()
{
int arr[MAX];
int i,n;
int val,pos;
printf("\nEnter total elements (n < %d) : ",MAX);
scanf("%d",&n);
printf("Enter %d Elements : ",n);
for(i=0;i
printf("\nLIST : ");
for(i=0;i
printf("\nSearch For : ");
scanf("%d",&val);
pos=interpolationsearch(&arr[0],0,n,val);
if(pos==-1)
printf("\nElement %d not found\n",val);
else
printf("\nElement %d found at position %d\n",val,pos);
return 0;
}
Contact Me on born2c0de AT dreamincode DOT net
*/
#include
#include
#define MAX 5
int interpolationsearch(int a[],int low,int high,int x)
{
int mid;
while(low<=high)
{
mid=low+(high-low)*((x-a[low])/(a[high]-a[low]));
if(x==a[mid])
return mid+1;
if(x
else
low=mid+1;
}
return -1;
}
int main()
{
int arr[MAX];
int i,n;
int val,pos;
printf("\nEnter total elements (n < %d) : ",MAX);
scanf("%d",&n);
printf("Enter %d Elements : ",n);
for(i=0;i
printf("\nLIST : ");
for(i=0;i
printf("\nSearch For : ");
scanf("%d",&val);
pos=interpolationsearch(&arr[0],0,n,val);
if(pos==-1)
printf("\nElement %d not found\n",val);
else
printf("\nElement %d found at position %d\n",val,pos);
return 0;
}
이진트리검색
#include
#include
#include
typedef struct node {
struct node* left;
char* word;
int count; // 추가 1
struct node* right;
} NODETYPE;
int insert_node(NODETYPE* root, char* str);
NODETYPE* search(NODETYPE* root, char* key);
void inorder(NODETYPE* root);
int main()
{
NODETYPE* tree = NULL;
NODETYPE* ptr;
char wbuf[30];
printf(" 검색 트리에 저장할 단어를 입력하세요.\n 입력의 끝에는 quit를 입력하세요.\n");
while( strcmp(gets(wbuf), "quit") ) {
if(!tree) { // 트리가 비었을 때
tree = (NODETYPE*)malloc(sizeof(NODETYPE));
tree -> word = (char*)malloc(strlen(wbuf)+1);
strcpy(tree->word, wbuf);
tree->left = tree->right = NULL;
tree->count = 1; // 추가 2
}
else
insert_node(tree, wbuf);
} // end while
printf("\n\nEnter a key to search : ");
gets(wbuf);
ptr = search(tree, wbuf);
if(ptr)
printf("%s is in this tree.\n\n", ptr->word);
else
printf("%s is not exist.\n\n", wbuf);
printf("---트리안의 단어들 (사전식 순서)----------------\n\n");
inorder(tree);
return 0;
}
NODETYPE* search(NODETYPE* root, char* key) {
NODETYPE* tptr = root;
int cmp;
while(tptr) {
cmp = strcmp(key, tptr->word);
if(cmp < 0)
tptr = tptr->left;
else if(cmp > 0)
tptr = tptr->right;
else // found
return tptr;
} // end while
return NULL; // not found
}
int insert_node(NODETYPE* root, char* word)
{
NODETYPE* tptr = root, *before;
int cmp = 0;
while(tptr) {
cmp = strcmp(word, tptr->word);
if(cmp < 0) {
before = tptr;
tptr = tptr->left;
}
else if(cmp > 0) {
before = tptr;
tptr = tptr->right;
}
else
(tptr->count)++; // 추가 3 빈도수
return 0;
} // end while
tptr = (NODETYPE*)malloc(sizeof(NODETYPE));
tptr->word = (char*)malloc(strlen(word)+1);
strcpy(tptr->word, word);
tptr->left = tptr->right = NULL;
tptr->count = 1; // 추가 4
if(cmp < 0)
before->left = tptr;
else
before->right = tptr;
return 1;
}
void inorder(NODETYPE* ptr)
{
if(ptr) {
inorder(ptr->left);
printf("%s \t %d\n", ptr->word, ptr->count); // 추가 5
inorder(ptr->right);
}
}
[출처] C언어 이진트리 검색|작성자 sangtakeg
2010년 10월 30일 토요일
Google: How We’re Making the Web Faster
Google: How We’re Making the Web Faster
June 23rd, 2010 : Rich Miller
Google's Urs Holzle speaking during his keynote presentation at the Velocity 2010 conference Wednesday in Santa Clara.
At last year’s Velocity conference, Google detailed how faster web pages were boosting its bottom line. This year the search giant is showcasing how it is using its software, servers and infrastructure to create a faster Internet – and calling on site owners to join the effort.
The average web page takes 4.9 seconds to load and includes 320 KB of content, according to Urs Hölzle, Google’s Senior Vice President of Operation. In his keynote Wednesday morning at the O’Reilly Velocity 2010 conference in Santa Clara, Calif., Hölzle was preaching to the choir, addressing a crowd of 1,000 attendees focused on improving the performance and profitability of their web operations.
‘Ensemble’ of Elements
“Speed matters,” said Hölzle. “The average web page isn’t just big, it’s complicated. Web pages aren’t just HTML. A web page is a big ensemble of things, some of which must load serially.”
At Velocity 2009 Google’s Marissa Mayer discussed how latency had a direct impact on Google’s bottom line. When Google’s pages loaded faster, Mayer said, users searched more and Google made more ad revenue. This year Hölzle discussed a broad spectrum of initiatives by Google to extend those benefits to the wider web. That includes efforts to accelerate Google’s own infrastructure, advance standards to speed the web’s core protocols and provide tools for site owners to create faster sites.
He cited the Chrome web browser as an example of how Google’s efforts can generate benefits for a larger audience. Chrome is designed for speed, Hölzle said, noting independent research that showed Chrome loading pages faster than competing browers.
N-screen 대응은 웹기술에 맡겨라
지금 가전 업체들의 가장 큰 고민은 N-screen 대응입니다. 즉 컨텐츠를 하나 만들어서 다양한 형태의 화면사이즈, 모바일폰, 태블릿, TV 에 대응이 되어야 한다는 것이죠. 제 강의를 들으신 분들은 아시겠지만 웹기술의 엄청난 강점인 Cross platfom 이나 Cross device 대응은 이제 기본입니다.
이제는 한번 만든 컨텐츠를 다양한 크기의 화면에 어떻게 대응 될것이냐가 정말 중요한 토픽입니다.
그런데 참 이런 문제를 해결해 주는 거의 유일한 기술이 바로 웹기술이라는 점이 우리 웹개발자들을 또 미소짓게 합니다.^^ 물론 Flash 나 Silverlight 도 가능하지요. 그러나 누누히 말씀드렸지만 대세는 웹이기 때문에 자연스럽게 웹기반으로 이런 문제를 해결하는 방법들을 찾고 있습니다.
당장 아이패드, 갤럽시 탭과 같은 태블릿이 나오면서 기존의 앱개발자들은 화면 해상도 대응하는 것에 지금 비상이 걸렸습니다.
그런데 우리 웹기술에는 이미 이런 내용들이 모두 준비되어 있죠.
- CSS3 Media query
원초적인 방식으로는 CSS media query 를 이용해서 각각의 화면사이즈에 최적화딘 컨텐츠를 보여주는 방법이 있구요. 물론 UI 가 좀 다르긴 하지만... - 일반적인 CSS 기법
하지만 능력좋은 웹개발자들은 media query 같은 것 안써도 CSS 만 가지고도 화면에 다 대응되게 코딩을 하시죠.
http://www.youtube.com/xl
위 사이트는 Youtube TV 용 페이지 입니다. 브라우저 크기를 움직이는 대로 모양과 비율이 모두 유지되면서 확대 축소 됩니다. - SVG(Sexy Vector Graphic) ㅎㅎ
그러나 이중에 대박중 초대박은 SVG(Scalable Vector Graphic)를 이용하는 것이지요. 날때부터 벡터그래픽입니다. 화면 해상도 크기 고민할 필요가 없는 것이죠. 유럽의 제조사들은 SVG 에 지금 엄청난 관심을 보이고 있습니다.
제가 웹이 대세라고 하는 것은 단순히 웹으로 앱을 개발할 수 있어서가 아닙니다.
가전의 거의 모든 분야에서 웹기술은 main stream 이 될 수 밖에 없습니다.
언제 이런 이야기 드릴 수 있는 기회가 있었으며 합니다.
HTML5
HTML5
- Web Forms 2.0 demo
- Canvas 2D : Drawing API
- Canvas demo
- video + CSS3 Transition
- video + canvas
- video control bar customization
- video javascript caption
CSS3
- CSS3 : border-radius
- CSS3 : text-shadow
- CSS3 Transition
- Webfonts demo
SVG
Java Collection
여태 개발하면서 무지 많이 써오던 컬랙션들. 성능이나 별다른 고민없이 걍 대충 써왔던 것 같다. "켄트 벡의 구현 패턴"이란 책을 보다 보니 자세한 설명이 있어서 그 동안 알고 있던것과 더불어 정리해 두는 게 조을 것 같다.
1. 인터페이스
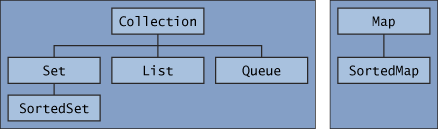
The core collection interfaces.
Queue는 거의 사용하지 않고 책에 없으니까 생략 ^^
- 배열
가장 단순하지만 가장 유연하지 못한 컬렉션.
크기가 고정되어 있고 원소 접근 방법이 용이하면 빠르다.
단순한 연산의 경우 배열은 다른 컬렉션에 비해 시간, 공간 모든 면에서 효율적이다.
일반적으로 배열 접근(element[i])은 ArrayList를 사용했을 때(elements.get(i))에 비해 10배 이상
빠르다고 한다.
대부분의 경우 유연성 문제 때문에 배열보다는 다른 컬렉션을 사용하고, 프로그램의 일부에서 성능이
중요한 경우 배열을 사용하는 것도 고려하는 것이 좋을 듯
- Iterable
기본적인 컬렉션 인터페이스로 순차 열람(iteration)을 지원한다.
어떤 변수를 Iterable로 선언하는 것은 그 변수가 여러 개의 값을 갖고 있음을 뜻할 뿐이다.
실제로 Iterable 인터페이스를 살펴 보면 자바 컬렉션의 모든 인터페이스, 구현 클래스들이 implement
하고 있는 것을 확인할 수 있고 Iterable에 정의된 메소드는 Iterator
Iterator를 이용하면 Iterator 인터페이스에서 지원하는 세가지 메소드
(hasNext(), next(), remove())를 사용할 수 있다.
자바 5에서는 암묵적으로 iterator() 메소드를 호출하여
for (Element element : elements) {
......
}
의 형식으로 간편하게 루프를 구성할 수 있게 한다.
실제 프로그램에서는 Iterable 인터페이스를 직접 사용할 일은 없으니 이런게 있다고 정도만 알아두면
될것이다.
- Collection
Iterable을 상속하며, 원소의 추가, 삭제, 검색, 크기 지원 등의 메소드를 추가로 지원한다.
- List
원소의 순서가 정의되어 있으며, 컬렉션상의 위치를 통해 원소에 접근할 수 있다.
따라서 List를 사용하면 컬렉션 상에서의 인덱스를 통해 어떤 원소를 접근 할 수 있다.
원소간의 순서가 중요한 경우, 예를 들어 도착 순서대로 메세지를 처리하는 큐의 경우에는 리스트를
사용해야 한다.
- Set
중복된 원소가 없는 컬렉션
중복원소(상호간 equals()의 결과가 참인 원소)를 허용하니 않는 컬렉션
원소 사이의 순서가 없으므로, 이전 순차 열람할 때의 원소 순서가 다음 순차 열람할 때 보장되지
않는다.
- SortedSet
중복된 원소가 없으며 원소간의 순서가 정해진 컬렉션
컬렉션에 추가된 순서나 명시적인 인덱스 번호에 따라 순서가 정해지는 List와 달리
SortedSet은 Comparator에 의해 순서를 정한다. 명시적인 순서를 제공하지 않는 경우에는
"자연 순서(natural order)"가 사용된다. 예를 들어 문자열은 알파벳 순으로 정렬
아래는 Comparator의 사용예
public Collection
Comparator
public int compare(Author o1, Author o2) {
if (o1.getLastName().equals(o2.getLastName())) {
return o1.getFirstName().compareTo(o2.getFirstName());
return o1.getLastName().compareTo(o2.getLastName());
}
};
SortedSet
for (Book each: getBooks()) {
results.add(each.getAuthor());
}
return results;
}
- Map
키에 의해 원소를 저장하고 접근하는 컬렉션
Map은 List처럼 키를 사용해서 원소를 저장하지만, List가 정수만을 키로 사용할 수 있는 반면
Map은 임의의 객체를 키로사용할 수 있다.
또 Map는 다른 컬렉션 인터페이스와는 형태가 상이하여 다른 컬렉션 인터페이스를 상속하지 않고,
내부적으로 키에 대한 컬렉션과 데이터에 대한 컬렉션의 2개 컬렉션을 유지한다.
컬렉션을 사용할 때는 항상 인터페이스를 선언하여 사용
List
Map
Collection 인터페이스를 사용하면 유연성은 가장 높겠지만 실제 사용한 적은 거의 없는 것 같다.
List, Set, Map이면 ㅇㅋㅂㄹ
2. 구현
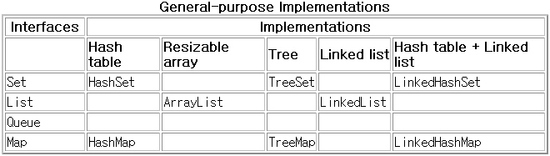
컬렉션에 대해 구현 클래스를 선택하는 것은 주로 성능과 관련이 있다.
위의 표에 소개한 구현 이외에도 무지하게 많은 구현들이 있다. 각 구현체의 특성을 살펴보고 필요한 것을
가져다 사용하면 된다.
일단 가장 단순한 구현을 사용하여 시작하고 추후 경험에 따라 튜닝하는 것이 좋다.
컬렉션중 가장 많이 사용되는 클래스는 ArrayList이며, 그 다음은 HashSet이다.
(이클립스와 JDK에서 ArrayList는 3400번, HashSet은 800번 사용되었다고 한다.)
- Collection 구현
Collection 인터페이스만 구현한 클래스는 없는 듯 하다. 단순한 컬렉션이 필요한 경우
그냥 ArrayList를 사용하자. ArrayList 사용시 성능상 문제되는 부분은 컬렉션의 크기에 비례해서
연산 시간이 커지는 contains(Ojbect)와 이 메소드를 이용하는 다른 메소드(remove() 등)이 있다.
이 때 중복 원소들을 제거해도 상관이 없다면 HashSet으로 교체하면 좋다. 그러나 중복 원소가 이미
없는 경우라면 별 차이가 없을 수도 있다.
- List 구현
ArrayList와 LinkedList
ArrayList는 원소 접근이 빠르고 원소 추가 및 제거가 느린 반면
LinkedList는 원소 접근이 느리지만 원소 추가와 제거는 빠르다.
- Set, SortedSet 구현
HashSet은 가장 빠르지만 원소간의 순서를 보장해주지 않는다.
LinkedHashSet은 원소 간 순서를 보장해 주지만 원소 추가 삭제 시 30% 정도 시간이 더 걸린다.
TreeSet은 Comparator에 따라서 원소를 정렬하지만 원소 추가 삭제 시간이
logn(n은 컬렉션의 크기)에 비례해서 커진다.
- Map 구현
Map 구현은 Set 구현과 비슷한 패턴을 보인다.
HashMap은 가장 빠르고 단순하다.
LinkedHashMap은 컬렉션에 추가된 원소 간의 순서를 보장한다.
TreeMap(SortedMap 의 구현)은 키의 순서에 따라 순차 열람이 가능하지만 원소의 추가 제거 시간이
logn(n은 컬렉션의 크기)에 비례한다.
3. Collections
Collections는 다른 컬렉션 인터페이스에 넣기 적절치 않은 기능들을 모아 놓은 유틸리티 클래스이다.
- 검색
indexOf() 연산에 걸리는 시간은 리스트의 크기에 비례한다. 원소들이 정렬되어 있을 경우
Collections.binarySearch(list, element)를 사용하여 log2n에 비례하는 시간에 검색할 수 있다.
원소가 리스트에 존재하지 않는다면 음수를 반환하고, 리스트가 정렬되어 있지 않다면 결과는 예측불가
- 정렬
reverse(list)는 리스트에 속해 있는 모든 원소 간의 순서를 거꾸로 바꾼다.
shuffle(list)는 순서를 임의로 바꾼다.
sort(list), sort(list, comparator)는 오름차순으로 원소를 정렬한다.
이진 검색과 달리 ArrayList와 LinkedList에서 정렬 수행 성능은 거의 같다. 정렬을 수행할 경우
컬렉션의 원소들이 일단 배열로 복사되어 정렬된 후 다시 본래의 컬렉션으로 복사되기 때문
- 수정 불가능한 컬렉션
신뢰할 수 없는 코드에 컬렉션을 전달하는 경우 Collections.unmodifiableCollection() 메소드를
이용하면 클라이언트가 수정하려 들 경우 예외를 발생시키도록 할 수 있다.
- 단일 원소 컬렉션
하나의 원소를 전달해야 하지만 컬렉션 인터페이스를 사용해야 하는 경우 사용
Set의 경우 Collections.singleton(T o), List와 Map의 경우 singletonList(T o),
singletonMap(K key, V value)를 사용
- 무원소 컬렉션
컬렉션 인터페이스를 사용해야 하지만 전달할 원소가 없는 경우에는 Collections에서 수정할 수 없는
무원소 컬렉션을 생성해서 사용
Collections.emptyList(), emptySet(), emptyMap()
- 동기화 컬렉션
이전 시대의 유물인 Vector와 Hashtable이 ArrayList와 HashMap간의 차이점은 전자가 쓰레드 안전인
반면 후자는 아니라는 것이다.
동기화가 필요없는 경우라면 ArrayList, HashMap을 사용하고 동기화가 필요한 경우
Collections.synchronizedCollection(), Collections.synchronizedList(),
Collections.synchronizedSet(), Collections.synchronizedMap()를 사용하여
ArrayList, HashMap을 래핑하면 멀티 쓰레드 환경에서도 걱정이 사라진다.
[출처] 자바 Collection|작성자 바람의 영혼
2010년 10월 26일 화요일
구글 크롬의 멀티프로세스 구조
먼저, 이전 크롬에 관한글에 서 잘못 적은 부분이 있었다. 크롬이 구현한 떼었다가 붙일 수 있는 동적 탭 기능이 멀티스레드 구조에서는 힘들다고 했는데 아니다. 오히려 멀티스레드 구조에서 손 쉽게 구현이 된다. 그냥 탑 레벨 Window 하나 만들면 끝이다. 스레드를 별도로 만들 수도 있지만 그럴 필요도 없다. 내가 단단히 착각을 했다. MFC의 기본 프로젝트 옵션 중에서도 “Multiple top level documents”라는 옵션이 이런 구현을 보여주고 있다.

오히려 크롬이 도입한 멀티프레세스 구조에서 하나의 창 아래 여러 프로세스의 내용을 묶는 것이 더 어렵다. 간략하게 구글 크롬에서 사용한 멀티프로세스 구조에 대해 이야기해보자.
멀티프로세스 구조의 장점과 단점은 잘 알 것이고, 이런 구조에서 어떤 방식으로 다른 프로세스들이 가지고 있는 데이터들을 최종적으로 화면에 잘 보여주는지 생각해보자. 먼저, 생각할 수 있는 방법으로는 어차피 프로세스 하나가 탭 하나씩 맏고 있으니까 그리는 것도 각자 알아서 처리하면 될 것 같다. 그러나 다른 프로세스에 있는 윈도우를 탭 컨트롤에 넣어 보이게 하는 것은 그렇게 간단치 않다. 윈도우 프로그래머라면 익숙한 SetParent(HWND) 함수로 다른 프로세스의 윈도우 핸들을 넣어버리면 되기는 되지만 다른 자잘한 문제들을 많이 만들어 낸다.1
그래서 대안으로 GUI를 처리하는 프로세스 하나가 있고, 나머지 웹 데이터를 처리하는 프로세스들이 서로 IPC를 통해 데이터를 주고 받는 방식을 떠올릴 수 있다. 브라우저에서 마우스를 클릭하면 이 메세지를 IPC로 해당 프로세스로 보내면 되고, 반대로 프로세스 내부에서 어떤 이벤트가 발생하면 다시 IPC로 전달해 최종적으로 UI를 바꾸도록 하면 될 것이다. 복잡한 프로그램을 짤 때 GUI와 엔진을 분리하는 전형적인 방식일 것이다.
직접 소스나 관련 문서를 찾아보기 전에 한 번 Spy++와 Process Explorer로 조사 해보자. 각각 두 탭씩 두 개의 브라우저 창을 띄었다. Spy++로 확인한 윈도우 구조는 아래와 같았다.

보다시피 Chrome_HWNDViewcontainer_0이라는 가짜 윈도우가 각 브라우저 창 마다 하나씩 존재하고 실제 창을 보여주는 윈도우는 Chrome_VistaFrame이라는 녀석이다. 이 아래에 현재 활성화된 창이 보여지고 있다. 그리고 비활성화 된 탭은 보다시피 hidden 상태(옅은 아이콘)로 있다.
그리고 중요한 것은 이 모든 윈도우들이 탭을 관리하는 프로세스들과 다른 별도의 한 프로세스로, 또 하나의 스레드 위에서 돌아간다는 점이다.2 그렇다면 이제 웹 페이지를 들고 있는 프로세스와 모든 창과 그리기를 담당하는 프로세스 사이에 IPC를 해야하는데 어떤 방식으로 할까? 무식하게 동기 방식인 WM_COPYDATA3 으로 구현할리는 만무하다. 그럼 아무래도 얘들은 CreateNamedPipe 같은 Win32 Named Pipe 객체로 IPC를 할 것 같다. Process Explorer로 확인해보니 각 자식 프로세스마다 named pipe를 하나씩 열고 있음을 볼 수 있다.

생각보다 복잡하지 않고 그냥 우리가 생각할 수 있는 ‘당연한’ 방법으로 구현했다. 그러나 핵심은 이런 기본적인 설계가 아니라 구현 자체에 있다. 비록 설계는 “흠.. GUI 프로세스 하나와 IPC로 하면 되겠군!” 이라고 간단히 그려져도 막상 구현에 들어가면 생각하지 못한 문제가 속출하는 등 많은 어려움이 있을 것이다. 이런 것을 극복하고 이렇게 잘 만드는 것은 분명히 다른 차원의 이야기다.
그럼 정답을 찾아보자. 구글 크롬은 Chromium이라는 오픈 소스로 관리되고 생각보다 많은 문서들이 있다. 멀티 프로세스 구조에 대해서도 꽤 자세히 잘 설명되어있다.

대략 예측한대로 ‘Browser’ 프로세스는 그림 그리기나 여러 마우스 이벤트를 관할하고, ‘Renderer’ 프로세스는 보다시피 웹 엔진 WebKit을 표현한다. 그리고 Named pipe 기반의 비동기 IPC를 통해 서로 데이터를 주고 받는다. 참고로 이 문서에 소개된 대표적인 IPC 경우를 예로 들어보자:
- Browser에서 Renderer로 가는 경우: 마우스 클릭과 같은 메세지. 이런 마우스 메세지는 Win32 윈도우 객체가 일단 받는다. 그런 뒤 플랫폼 독립적인 형태로 바꿔 Renderer로 보낸다.
- Renderer에서 Browser로 가는 경우: 중 마우스 커서 모양을 바꾸라는 신호. 이 신호는 분명 내부 웹 엔진인 WebKit이 만들어야 할 것이다. 이걸 브라우저가 IPC로 받아 GUI가 그에 맞게 커서를 보여준다.
물론 자세히 소스를 까보면 복잡하겠지만 역시 큰 그림은 이해가 쉽다.
생각보다 Chromium의 문서들이 참 설명이 잘 되어있어 이해하기 쉽다. 자고로 소스 코드를 읽고 이해하는 것 보다 새로 짜는 것이 더 편하다는 말이 있을 정도로 소스 읽기는 암호 해독 수준이다. 오픈소스를 지향하면 그 만큼 이 부분을 해결해야하는데 많은 기술 문서 뿐만 아니라 디버깅 방법까지 친절히 알려주고 있다. 크롬은 멀티 프로세스라서 디버깅이 그리 간단치 않기 때문이다. 이런 친절함은 곧 공짜로 전세계 (순전한) 프로그래머들의 노동력을 착취하겠다는 소리..
결론: 이 Browser 프로세스를 죽이면 (혹 여기서 버그가 나면) 그냥 모든 탭도 다 같이 죽어버린다 ㅎㅎ
추가: 크롬은 한 탭에 뜬 페이지라 하더라도 플러그인을 다른 프로세스로 돌리기 때문에, 그 플러그인이 죽었을 때 페이지가 죽지 않도록 하고 있습니다. 이 부분은 아주 좋은 아이디어였습니다. 그리고 반드시 모든 탭이 각각 하나의 프로세스로 대응되는 것은 아니었습니다. 탭을 40~50개 띄어보면 제한된 프로세스 풀에서 할당되어있음을 볼 수 있습니다.
1. 대표적인 SSH 클라이언트인 Putty는 멀티탭 구현이 없다. 그래서 여러 멀티탭 구현이 존재하지만 제대로 작동하지 않는다. 모두 다른 프로스세에서 돌아가는 창을 무리하게 한 윈도우로 넣으려고 하기 때문이다.
2. Spy++로 해당 윈도우가 어느 프로세스/스레드 위에 만들어졌는지는 간단히 알 수 있다. Windows 운영체제에서 Window 객체가 어느 스레드 위에 만들어졌는가는 꽤 중요하다. 보통은 primary thread에서만 만들어지기 때문에 별 신경을 안쓰지만 멀티스레드로 갈 경우에는 이것을 중요하게 따져야 한다. 메세지 큐가 per thread로 존재하기 때문에 스레드 넘어 있는 윈도우를 조작할 때 자칫하다 데드락이 발생할 수도 있다.
3. WM_COPYDATA는 서로 다른 프로세스에게 데이터를 전달할 수 있는 가장 간단한 동기 IPC 방법이고 SendMessage로만 가능하다. 생각보다 WM_COPYDATA도 동기적인 IPC에서는 꽤나 편하고 정확하게 작동한다.
[출처] 구글 크롬의 멀티프로세스 구조|작성자 쵸비츠
5년 후의 웹 브라우저
특히, 자의반 타의반 HTML5가 애플과 어도비의 해묵은 기술 및 비즈니스 논쟁에 끼어 들면서 '웹 vs. 앱' 혹은 '웹 vs. Flash(플러그인)'이라는 구도의 마케팅 용어로 변질되고 있는 느낌 마저 든다.
게다가 iUi를 만든 Joe Hewitt은 "플래시 보다는 웹의 혁신을 느리게 진행한 W3C와 브라우저 벤더를 탓하라"는 트위터 논쟁이 있은 뒤라 더더욱 그렇다. (한국에서는 좀 더디지만) 2004년 부터 시작된 2차 웹 브라우저 전쟁과 웹 표준을 기반한 기술 혁신은 과거에 비해 훨씬 빠른 속도로 진행되어 왔다.
이 럴 때 일 수록 웹 개발자들은 의연히 대처할 필요가 있다. 내가 왜 웹 개발자가 되었으며 웹이 가진 개방성이 우리에게 주는 의미를 한번 더 되새기면서 말이다. 그리고 HTML5가 만드는 혁신에 서서히 몸을 맡길 준비를 할 필요가 있다.
이 런 이유에서인지 올해 샌프란시스코에서 열린 웹2.0엑스포는 페이스북이나 트위터 같은 소셜 웹 서비스와 HTML5 같은 웹 기술 혁신으로 인해 훈풍이 불고 있는 듯 하다. 아래 글은 행사 중 웹 브라우저 벤더의 주요 개발자들이 참여한 "미래의 웹 브라우저" 패널 토의를 TechCrunch가 요약한 것이다.

패널리스트
— Douglas Crockford (Yahoo) 자바스크립트 구루, JSON 창시자
— Brendan Eich (Mozilla) 자바스크립트 창시자, Mozilla 기술 이사
— Charles McCathieNevile (Opera) - 웹 표준 임원, W3C WebApps W/G 의장
— Alex Russell (Google) 크롬프레임 개발자, Dojo 툴킷 개발자
— Giorgio Sardo (Microsoft) 웹 기술 에반젤리스트
— 좌장: Dion Almaer(Palm)와 Ben Galbraith (Palm): Ajaxian.com 공동 설립자
Q: IE9에서 캔버스 기능을 보고 싶은분 손 들어달라!
* MS 직원은 Sardo를 포함해 전원이 손을 들다*
Sardo (Microsoft)— 아직 구현을 못했지만 HTML5에 열심히 투자하고 있다. 고급 수준의 구현을 하려면 개발자에게 피드백도 받고 스펙도 잘 읽고 성능과 호환성에도 신경 써야 한다. 아마 모든 게 하드웨어 가속을 써야 할 것 같다
Almaer (Palm)— 내 생각엔 SVG에 비해 캔버스는 구현이 간단해 보인다만...
Eich — SVG 구현은 거대하지만 캔버스는 간단하다. 우리는 5년 전 부터 이걸 해 왔지만 꽤 간단하다.
Almaer (Palm)— 어떻게 IE6에서 일어난 문제를 다시 겪지 않을 것인가?
Russell (Google)— IE9가 정말 기다려 진다. 하드웨어 가속 SVG와 렌더링. 경쟁은 좋은 것이고 기본이다. 웹 브라우저들이 사용자들의 요구에 맞게 경쟁하고 진화하면 좋겠다. 이런 시스템이 동작하면 구현은 더 빨라질 수 있다. 2001년의 IE6은 멋졌지만 문제는 더 나아가지 못하고 중단했다는 것이다. 우리는 변화의 중간에 있다. 그 갭을 메꾸는데 장기 방안은 아니지만 플러그인이 그 대안이 될 수 도 있다. (역자주: 얘가 크롬프레임을 만든 애인데, 그의 방식은 그렇게 좋은 방법은 아니다.)
Q: 웹 브라우저 벤더 모두 같은 스펙을 구현하고 있는데 우선 순위는?
McCathieNevile (Opera)— 우리는 개발자들과 대화 한다. 사람들이 무엇을 쓰는지 먼저 본다. 개발자들이 원하는 것을 먼저 만든다.
Eich — Mozilla는 10년간 오픈소스로 개발해 왔다. 실제로 구현을 해 주는 외부 개발자 그룹도 가지고 있다. 요즘에는 Web Form에 관심을 가지고 있고, HTML5의 많은 부분도 구현하고 있다. 웹 개발자들이 C++코드를 제공하지는 않지만 무엇이 문제인지는 계속적으로 의견 교환을 한다.
Q: Doug, 변화의 필요성에 대해 계속 강제해 왔다.
Crockford (Yahoo)— 웹은 2000년에 죽은 채 내버려졌다. Microsoft나 많은 사람들은 웹이 끝났다고 생각했다. 이 때 (Flash 같은) 몇 가지 웹 개발 플랫폼이 나타났지만, 2005년에 웹은 Ajax로 부활했다. 웹 브라우저는 매우 중요한 애플리케이션 배포 도구가 되었는데도, 불행하게도 W3C는 그 역할을 포기했다. 우리는 지금 1999년의 웹 표준 상태에서 아직 벗어나지 못하고 있다. 개발자들은 조금씩 전진해 나가려고 하지만 IE6 같은 문제를 풀지 않으면 안된다. 국제적으로 어떤 곳은 40~60%나 된다. IE6 문제는 주요 웹 사이트 개발자들이 풀어 주어야 한다. 특히 ActiveX 기반 웹 사이트도 문제다. 이걸 대체하지 않으면 IE6 대체도 어렵다. 중국 같은 나라의 경우 해적판 운영 체제를 쓰는 것도 문제다.
Sardo (Microsoft)— 윈도우 업데이트 중 일부가 정식 라이센스 구매자에게만 제공 되긴 하지만 IE는 예외이다. 해적판 사용자도 IE를 설치할 수 있다. 다만 IE9은 XP는 지원하지 않는데, 이는 HTML5 하드웨어 가속을 최신 운영 체제에서 지원 가능하기 때문이다.
Russell (Google) — Opera나 Mozilla이나 Chrome이나 모두 하드웨어 가속을 준비 중이다. 특히 XP에서도 구현하고 있다. MS가 말한 것은 사용자를 위한다고 하지만 사용자 뒤에 숨는 것과 비슷하다. 결국 질문은 우리가 웹 개발자들이 HTML5를 선택 할 수 있는 기회를 잘 주느냐 하느 것이다.
Crockford (Yahoo)— 모든 윈도XP 사용자들이 IE말고 다른 브라우저를 쓰면 되겠네.. ㅎㅎ
McCathieNevile (Opera) - 최신 하드웨어가 아닌 하드웨어도 있다. 이게 사용자들이 XP에서 업그레이드를 못하는 이유기도 하다. 많은 사람들은 기술적인 업그레이드를 원하지는 않는다.
Q: 웹 브라우저 경쟁에 대해 이야기해 보자. 오랫동안 Mozilla Firefox는 IE의 대안으로 위치를 점했다. 이제 여러 웹 브라우저들이 점점 혁신을 해 나가는데 Firefox의 입장은 뭔가?
Eich (Mozilla)— 우리는 선택과 혁신을 지속하자는 사명이 있다. 사용자들의 경험이 최고의 가치다. 물론 경쟁이 치열하다. 하지만 문제는 "상용 벤더"는 (기업의) 목적이 있다. 애플은 좋은 제품을 만들지만 개발자들이 쓰는 SDK나 API를 통제하려고 한다. 구글은 오픈웹의 경향을 띠고 있지만 검색에 맞는 것만 한다. Mozilla는 이런데 신경 안쓴다. 우리는 스스로 눈을 감고 데이터를 보지도 마케팅에 신경쓰지도 않는다. 요즘 페이스북이 하는 짓거리를 보라. 사용자들은 (회사의 이익과 관계 없이) 스스로 데이터 통제와 선택권한을 가질 필요가 있다.
Q: 자바스크립트의 상태는 어떤가?
Eich (Mozilla)— 표준 위원회는 싸우지 않고 조화롭게 잘 굴러가고 있다. 제안 사항을 프로토타입으로 만들고 있고 모듈 시스템 처럼 협력해서 진행 중이다.
Russell (Google) 해석기(Interpreters)들이 점점 빨라진다. 아마 더 빨라질 것으로 보이지만, 네트웍 보다 빠르진 못해서 SPDY라고 불리는 새 프로토콜을 제안했다. 근본적인 레이턴시가 로컬 디바이스 성능 만큼 안 나온다. 웹 브라우저 프로세스를 개선하고 DOM 그자체도 업그레이드하고 있다.
Sardo (Microsoft)— 모든 웹브라우저가 좋은 자바스크립트 성능을 보이고 있지만 좀 더 개선의 여지는 있다.
Q: 여기서 Joe Hewitt이 이번주에 트위터에서 한 이야기 좀 해봐야 겠다. 그는 "난 웹을 사랑하지만 개판이다"라고 했다. (플래시 같은) 상용 플랫폼을 보면 굉장히 진화하고 있다. 아마 Joe는 이런 느슨한 시스템 때문에 웹 표준이 제대로 동작하지 않는다고 말했다.
Russell (Google)— 난 Joe가 만든걸 매우 좋아하는 사람으로서 존경하고 그의 생각에 동감한다. 내가 자바스크립트 툴킷을 다뤄 보니 진짜 골치아팠다. 그도 비슷했을 것이다. 하지만 그건 2년전의 이야기이다. 웹킷을 보면 훨씬 많이 나아졌다. CSS 애니메이션 같은 iUi의 많은 문제점이 해결됐다. 더 많은 기능이 계속 구현 중이고 그 향상 속도는 점점 빨라진다.
Q: 모바일 브라우저와 터치 인터페이스에서도 뭔가가 필요한것 같다. 다들 어떻게 진행 중인가?
Eich (Mozilla)— Firefox를 모바일에 탑재하는 작업을 진행 중인데 데스크톱에서 걱정되는게 많다는 점은 동의한다. 멀티 터치에 관한 한 애플은 멋지다. 문제는 빨리 표준화 할 필요가 있다는 점이다. 대부분 구현이 아이폰에서 만들어졌는데 (비록 애플이 Cocoa를 원했었더라도) 웹에서 구현될 수 있게 되었다. 이런 것이 꽤 도움되는 일이다. Joe가 말했듯이 많은 사람이 한 방에 들어차 있는 문제가 있다. 이건 혁신을 위해서도 안 좋다. 모바일에서 문제는 멀티 코어 지원에 대한 것이다. 아마 차세대 주요 문제로 웹에도 영향을 미칠 것이다. 이런 미래에 대해서는 준비가 안되었다. 아마 향후 5년간 자바스크립트 측면에서는 큰 이슈거리다.
Q: 오페라 모바일 브라우저를 아이폰에 탑재한건 어떻게 진행 되었나?
McCathieNevile (Opera) — 우리는 몇 억건의 웹 브라우저를 배포했다. 아이폰에 탑재된 오페라 미니는 사실은 아이폰 같은 스마트폰을 못쓰는 사람들을 위해서 만든 것이다. 일반 폰에서 웹 페이지를 보기 위한 것으로 아이폰의 전략과 맞지 않다. 더 많은 사람들이 다양한 웹 브라우저를 쓰게끔 하기 위한 전략일 뿐이다.
Q: 90년대에 3개의 웹 브라우저만 지원하면 됐었다. 이제 6개나 되는데 어떻게 웹 사이트를 만들어야 하나?
McCathieNevile (Opera)— 표준화에서 중요한 점은 더 나은 표준을 만드는 것이다. 하위 호환성을 유지해주는게 중요하다. HTML5는 웹을 뒤집어 엎을려는 게 아니라 다시 시작하기 위한 것이다. 유지하면서 개선을 진행하는 것이다.
Crockford (Yahoo)— 모바일로 옮아갈 때 큰 문제라고 생각하고 걱정되는 것이 "개방성"을 잃어 버릴까 하는 점이다. 웹이 충분히 혁신하지 못해 상용 앱 플랫폼이 이기거나, 그 반대가 될 텐데...
[Sardo (Microsoft)는 호환성 극대화를 위해 렌더링 엔진간 변환 가능성과 표준에 대해 이야기했다. Crokford의 이야기는 논쟁 거리가 되어서 몇 가지는 건너 뛰었다.]
Russell (Google) —새 웹 브라우저에 대해 과거 콘텐츠를 유지하는 건 경제적 비용이 든다. 옛날 기술에 익숙한 사용자들도 기업에게는 비용이다. 렌더링 엔진을 변경 가능하게 하는 것이 웹 사이트 생태계를 좀 더 빠르게 바꿀 수 있는 방법이다.
===========================
결국 웹의 혁신은 HTML5나 플래시가 아니라 사용자와 개발자에게 달려 있다. 지금 웹이 원하는 방향은 높은 생산성으로 웹 문서와 웹 애플리케이션이 동시에 제공 되는 것이다.
많 은 사람들은 어리석게도 HTML5가 초안 상태(Draft)이며, 완벽히 구현 되려면 수 년~수십 년이 걸릴 것이라고 말한다. 하지만, 웹 표준 '스펙의 완벽함'과 구현은 전혀 별개이다. 10년 전 만들어진 W3C 스펙이 아직까지 구현되지 않은 것도 많다.
늘 그렇듯이 HTML5에서 사용자와 개발자들이 요구하는 주요 기능은 빠르게 구현되어, 데스크톱 뿐만 아니라 다양한 모바일 디바이스에 빠르게 적용될 것이다. 상용 벤더 뿐만 아니라 (Mozilla와 같은) 선택 가능한 기술적 대안들이 혁신을 더 빠르게 촉진할 것 같다. 이것이 90년대 IE vs. Netscape 시절과 전혀 다른 점이고, 어도비가 HTML5 저작 도구 개발에도 힘쓸거라고 말하는 이유다.
5년 후 웹의 모습은 우리가 지금 보는 것과 완전히 다른 새로운 것이 될 것이고, 그 청사진은 이미 우리가 보고 있다.
브라우저에서 그래픽 가속하기
브라우저가 단순히 컨텐츠를 탐색하고 보여주는 애플리케이션이라는 울타리를 벗어나, 또 다른 애플리케이션을 실행하기 위한 플랫폼으로 발전하고 있다. 하지만, 현재 구현된 브라우저 엔진만으로 플랫폼 역할을 하기에는 넘어야할 한계가 있는데, 바로 성능과 안정성 확보다. 이를 위해 각 브라우저 벤더는 아래 3가지 측면에서 여러 기술을 브라우저에 도입하고 있다.
1) 다중 프로세스(Multiple Process) 적용
2) 자바스크립트 가속
3) 그래픽 하드웨어 가속
위 세가지 기술은 아직까지 안정화가 필요한 부분도 있지만, 대다수의 브라우저 이미 적용했거나 적용을 준비 중에 있다. 우선, IE9덕에 많은 분들이 관심을 갖고 있는 "그래픽 가속"에 대해 알아보자.
브라우저에 HTML5, CSS3가 본격적으로 적용되면서 웹에서 표현할 수 있는 컨텐츠의 종류가 다양해졌다. 최근에는 WebGL에 표준화되면서 3D까지 지원하게 되면서, 2D뿐만 아니라 3D도 가속해야할 상황에 도달했고, 애플 iPad로 촉발된 HTML5 Video지원도 그래픽 가속 없이는 브라우저에서 HD영상을 재생하기에는 무리였다. 그런데, 마이크로소프트에서 IE9 베타에서 하드웨어 그래픽 가속를 강력하게 표면화 시키면서, 이에 대한 논쟁이 가열되고 있다. 지금까지 가장 빠른 브라우저는 구글의 크롬(Chrome)이라는 공식에 역습을 가한 것이다.
1) 다중 프로세스(Multiple Process) 적용
2) 자바스크립트 가속
3) 그래픽 하드웨어 가속
위 세가지 기술은 아직까지 안정화가 필요한 부분도 있지만, 대다수의 브라우저 이미 적용했거나 적용을 준비 중에 있다. 우선, IE9덕에 많은 분들이 관심을 갖고 있는 "그래픽 가속"에 대해 알아보자.
브라우저에 HTML5, CSS3가 본격적으로 적용되면서 웹에서 표현할 수 있는 컨텐츠의 종류가 다양해졌다. 최근에는 WebGL에 표준화되면서 3D까지 지원하게 되면서, 2D뿐만 아니라 3D도 가속해야할 상황에 도달했고, 애플 iPad로 촉발된 HTML5 Video지원도 그래픽 가속 없이는 브라우저에서 HD영상을 재생하기에는 무리였다. 그런데, 마이크로소프트에서 IE9 베타에서 하드웨어 그래픽 가속를 강력하게 표면화 시키면서, 이에 대한 논쟁이 가열되고 있다. 지금까지 가장 빠른 브라우저는 구글의 크롬(Chrome)이라는 공식에 역습을 가한 것이다.
과연 브라우저에서 그래픽 가속이 어떤 의미있고, 현재 어느 수준까지 지원되고 있는지 살펴보도록 하겠다.
그래픽 가속이란?
일반적으로 화면에 어떤 그래픽 요소를 표현하려면, CPU가 계산한 그래픽 데이터를 메인 메모리에서 Frame Buffer로 복사해야 한다. 그래픽 가속이란, 이를 CPU가 아닌 그래픽 가속기(GPU)에 전달된 명령어를 실행하여 하드웨어적으로 처리하여 성능을 높인 것을 말한다. 즉, 그래픽 연산 부터 생성된 데이터를 Frame Buffer로 복사하는 모든 과정을 GPU에서 알아서 처리한다. 그 사이 CPU는 HTML을 다운로드 받고 파싱하는 등 다른 작업을 처리할 수 있다. 참고로, GPU는 CPU와 달리 데이터 병렬성이 풍부해 큰 데이터량을 한번에 계산하는데 효율적이므로, 3D 벡터 데이터나 멀티미디어 데이터 처리에 유리하다.
그래픽 가속의 종류
그래픽 가속에는 크게 2D, 3D, Video 가속으로 나눌 수 있다. 먼저 2D 가속으로 2D 벡터 그래픽, 이미지 프로세싱/디코딩/인코딩, Font Glyph Caching 등을 지원할 수 있다. 2D 벡터 그래픽은 OpenVG라는 표준 API가 존재하고 이를 지원하는 HW가속칩도 존재하지만, 많이 활용되고 있지는 않다. 현실적으로 2D가속은 CPU에서 제공하는 SIMD 연산와 OpenGL과 같은 3D 라이브러리에 의존하고 있습니다. 참고로, SIMD는 Single Instruction, multiple data의 약자로서 하나의 명령어로 여러개의 값을 동시에 계산하는 방식을 말하며, alpha brending이나 Video Format의 color space 변환 등에 사용한다. ARM Coretex A시리즈에서는 NEON이라고 부르는 SIMD연산을 지원한다[1].비디오 가속의 경우, 모바일 환경에서는 전용 디코더를 하드웨어적으로 내장하는 경우가 많고, PC환경에서는 GPU를 사용한다. 만약 디코더가 내장되어 있지 않은 경우에는, CPU에서 제공하는 SIMD연산을 사용하기도 한다.
3D 그래픽은 OpenGL이라는 표준 API 규약을 이용하여 구현한다. Mesa3D라고 SW적으로 구현된 OpenGL 라이브러리도 있지만[2], GPU벤더들이 자사 GPU에 최적화된 OpenGL 라이브러리를 제공하기 때문에, OpenGL API만 잘 사용해도 쉽게 가속이 가능하다. 윈도에서는 DirectX를 이용해서 3D가속을 한다. 특히, DirectX 10버전에는 Font Glyph를 GPU memory에 cache하고 GPU에서 Anti-aliasing을 처리하여 폰트 출력를 획기적으로 향상시켰다[3].
브라우저에서 그래픽 가속
위 그림은 WebKit을 예로 하여, 그래픽 가속 관점에서 브라우저 아키텍쳐를 그려보았다. 이 아키텍쳐는 주로 모바일 프로세서를 사용하는 아이폰이나 안드로이드폰에서 볼 수 있으며, PC에서는 사실상 모든 그래픽 작업을 GPU에서 처리할 수 있다. 위 그림을 통해 브라우저에서 표현하는 그래픽 요소가 어떤 라이브러에 의존하여 렌더링되고 어떤 HW를 통해 가속되는지 한 눈에 확인할 수 있다. PC의 경우 GPU에서 직접 H.264 비디오를 디코딩할 수 있으나, 아직까지 Mobile에서는 인코더/디코더를 하드웨어적으로 구현하여 사용한다[4].
앞에서 언급했듯이 2D 벡터 그래픽은 GPU로 가속이 가능해서 위 그림에 이를 표현하였고, 마찬가지로 SIMD연산을 이용해서 VIDEO가속도 일부 가능하므로 역시 이를 그림에 반영하였다.
다음에는 브라우저별 그래픽 가속 현황을 살펴볼 예정이다.
브라우저 하드웨어 가속
웹브라우저들이 다음 발전의 방향을 하드웨어
가속으로 설정하는 분위기이다. 이를 응용하면 한결
개선된 그래픽 환경을 만들 수 있어 이 부분에서
경쟁이 심화될 것으로 예상된다.
인터넷이 점점 더 현란하고 화려한 그래픽과 동영상을 실시간으로 전송할 수 있게 될 수록, 또 조금 더 사용자 편의적인 인터페이스를 갖춰 갈 수록 소프트웨어의 능력 만으로 이를 구현하는 데 버거워질 수 밖에 없는 것이 현실이다.
이런 문제의 효과적인 해결 방법은 역시 웹브라우저가 하드웨어 가속 기능을 적극 이용하는 것이라 생각해 볼 수 있는데, 마이크로소프트 역시 자신들의 다음 익스플로러 버전에 하드웨어 가속 기능을 사용할 것을 고려 중이라 밝힌 바 있다.
어쩌면 이를 응용하는 브라우저들이 일반화되면 향후 웹 환경은 또 한번 급속히 변화될 지도 모를 일인데, 그만큼 빠른 그래픽 등의 처리가 가능해지므로 개발자들은 조금 더 여유 있는 그래픽이나 동영상, 또는 GUI등을 웹을 통해 구현할 수 있게 된다.
현재 모질라는 파이어폭스에 Direct2D와 DirectWrite 등의 기능을 활용하는 방안을 연구 중이며, 구글의 크롬 역시 하드웨어 가속 기술의 채용을 위해 동분서주 하고 있는 모습. 여기에 마이크로소프트의 인터넷 익스플로러까지 가세하고 나면 웹브라우저간 차기 전쟁의 승패는 바로 '하드웨어 가속' 부분이 될지도 모를 일이다.
누가 가장 먼저 이를 구현해 낼지는 조금 더 지켜 보아야 하겠지만, 현 시점에서 보면 모질라가 이 분야에서 가장 앞서가고 있는 듯 보인다. 여기에 마이크로소프트의 IE9는 Windows 8이 완성되는 2011년 경에 등장할 것으로 점쳐지며, 그 중간쯤에 구글의 크롬 역시 이를 지원하기 시작할 것으로 예상된다. - 케이벤치(www.kbench.com)
가속으로 설정하는 분위기이다. 이를 응용하면 한결
개선된 그래픽 환경을 만들 수 있어 이 부분에서
경쟁이 심화될 것으로 예상된다.
인터넷이 점점 더 현란하고 화려한 그래픽과 동영상을 실시간으로 전송할 수 있게 될 수록, 또 조금 더 사용자 편의적인 인터페이스를 갖춰 갈 수록 소프트웨어의 능력 만으로 이를 구현하는 데 버거워질 수 밖에 없는 것이 현실이다.
이런 문제의 효과적인 해결 방법은 역시 웹브라우저가 하드웨어 가속 기능을 적극 이용하는 것이라 생각해 볼 수 있는데, 마이크로소프트 역시 자신들의 다음 익스플로러 버전에 하드웨어 가속 기능을 사용할 것을 고려 중이라 밝힌 바 있다.
어쩌면 이를 응용하는 브라우저들이 일반화되면 향후 웹 환경은 또 한번 급속히 변화될 지도 모를 일인데, 그만큼 빠른 그래픽 등의 처리가 가능해지므로 개발자들은 조금 더 여유 있는 그래픽이나 동영상, 또는 GUI등을 웹을 통해 구현할 수 있게 된다.
현재 모질라는 파이어폭스에 Direct2D와 DirectWrite 등의 기능을 활용하는 방안을 연구 중이며, 구글의 크롬 역시 하드웨어 가속 기술의 채용을 위해 동분서주 하고 있는 모습. 여기에 마이크로소프트의 인터넷 익스플로러까지 가세하고 나면 웹브라우저간 차기 전쟁의 승패는 바로 '하드웨어 가속' 부분이 될지도 모를 일이다.
누가 가장 먼저 이를 구현해 낼지는 조금 더 지켜 보아야 하겠지만, 현 시점에서 보면 모질라가 이 분야에서 가장 앞서가고 있는 듯 보인다. 여기에 마이크로소프트의 IE9는 Windows 8이 완성되는 2011년 경에 등장할 것으로 점쳐지며, 그 중간쯤에 구글의 크롬 역시 이를 지원하기 시작할 것으로 예상된다. - 케이벤치(www.kbench.com)
앱스토어 등록하고 소스코드를 공개한 앱
http://maniacdev.com/2010/06/35-open-source-iphone-app-store-apps-updated-with-10-new-apps/
1. ABC 123 – Sequence memorization game. Utilizes Cocos2D. (itunes link) (source code)
*2. Artifice – Strategy game where you try to get to the other side by moving boxes out of the way. Utilizes Cocos2D. (itunes link) (source code)
3. Colloquy – Conversion of the most popular Mac IRC client to the iPhone. (itunes link) (source code)
*4. Countitout - A generic counting app. (itunes link) (source code)
5. Diceshaker - Dice rolling simulator designed for role-playing game enthusiasts. (itunes link) (source code)
6. Doom Classic - Classic 3D first person shooter. (itunes link) (source code) (build instructions)
*7. Ecological Footprint - Calculate, display, and record your ecological footprint. (itunes link) (source code)
8. Fosdem - Calendar app for the Fosdem open source conference. (itunes link) (source code)
9. Freshbooks – App that enables usage of Freshbooks web invoicing software from your iPhone. (itunes link) (source code)
10. Gorillas – Classic Worms/iShoot turn based shooter type game converted to iPhone from basic. Utilizes Cocos2D. (itunes link) (source code). 1249ouFh83XA
11. Go Go Lotto – Open source lotto ticket generator. (itunes link) (source code)
12. iStrobe - Turns the iPhone 4 flash into a highly configurable strobe light. (itunes link) (source code)
13. Last.fm – Software that enables usage of the Last.fm platform for personal radio stations. (itunes link) (source code)
14. Mobilesynth - A monophonic synthesizer designed for live performance. (itunes link) (source code)
15. Molecules – Allows you to view 3D models of molecules and manipulate them through touch. (itunes link) (source code)
16. Mover – Allows you to transfer stuff from one iPhone to another by “flicking” it to the other device. (itunes link) (source code)
17. Natsulion - A basic twitter client converted from mac. (itunes link) (source code)
18. NowPlaying – Allows you to check local theater listings, and check rotten tomato ratings. (itunes link) (source code)
19. Packlog – Backpack journal client. (itunes link) (source code)
20. PlainNote - Simple Open Source Notepad. (itunes link) (source code)
21. PocketFlix – Find movies, and manage your Netflix information. (itunes link) (source code)
22. NevoChess – A Xiangqi game. (itunes link) (source code)
23. reMail – E-mail client featuring ultra-fast search. Removed from app store, but source made available. (source code)
24. RobotFindsKitten – Port of a very silly “classic” ASCII game. (itunes link) (source code)
25. Sci-15 HPCalc – Calculator app based on classic scientific HP-Calculator. (itunes link) (source code)
26. SpaceBubble – Space game featuring core graphics, and accelerometer usage. (itunes link) (source code)
27. Star3Map – Augmented reality star and planet charting application. (itunes link) (source code)
28. Task Coach – Personal to-do list and task manager. (itunes link) (source code)
29. Tubestatus – London train schedule tracker. (itunes link) (source code)
30. Tweejump – Platform jumping game inspired by Icy Tower. Utilizes Cocos2D. (itunes link) (source code)
31. Tweetee – Enhanced version of the Natsulion Twitter Client. (itunes link) (source code)
32. Tweetero – Basic twitter client with image uploading. (itunes link) (source code)
33. Twitterfon – Super-fast intuitive twitter client. (itunes link) (source code)
34. ViralFire – Unique game where you are a dodging blood cell. (itunes link) (source code)
35. Wikihow – A reader app for the popular how to wiki site. (itunes link) (source code)
36. Wolfenstein 3D Classic Platinum – If you haven’t heard of Wolfenstein post below so we can say a prayer for you. (itunes link) (source code)
37. WordPress – Client for managing WordPress blogs. Also has an iPad version. (itunes link) (source code)
38. YourRights – Pocket database containing a summary of your legal rights. (itunes link) (source code)
39. ZBar – A barcode reader. (itunes link) (source code)
2010년 10월 25일 월요일
Just-in-time compilation
Just-in-time compilation
From Wikipedia, the free encyclopedia
For other uses, see Just In Time (disambiguation).
| This article needs additional citations for verification. Please help improve this article by adding reliable references. Unsourced material may be challenged and removed. (November 2007) |
In computing, just-in-time compilation (JIT), also known as dynamic translation, is a method to improve the runtime performance of computer programs. Traditionally, computer programs had two modes of runtime operation, either interpreted or static (ahead-of-time) compilation.[citation needed] Interpreted code is translated from a high-level language to a machine code continuously during every execution, whereas statically compiled code is translated into machine code before execution, and only requires this translation once.
JIT compilers represent a hybrid approach, with translation occurring continuously, as with interpreters, but with caching of translated code to minimize performance degradation. It also offers other advantages over statically compiled code at development time, such as handling of late-bound data types and the ability to enforce security guarantees.
JIT builds upon two earlier ideas in run-time environments: bytecode compilation and dynamic compilation. It converts code at runtime prior to executing it natively, for example bytecode into native machine code.
Several modern runtime environments, such as Microsoft's .NET Framework and most implementations of Java, rely on JIT compilation for high-speed code execution.
Contents[hide] |
[edit]Overview
In a bytecode-compiled system, source code is translated to an intermediate representation known as bytecode. Bytecode is not the machine code for any particular computer, and may be portable among computer architectures. The bytecode may then be interpreted by, or run on, a virtual machine. A just-in-time compiler can be used as a way to speed up execution of bytecode. At the time the bytecode is run, the just-in-time compiler will compile some or all of it to native machine code for better performance. This can be done per-file, per-function or even on any arbitrary code fragment; the code can be compiled when it is about to be executed (hence the name "just-in-time").
In contrast, a traditional interpreted virtual machine will simply interpret the bytecode, generally with much lower performance. Some interpreters even interpret source code, without the step of first compiling to bytecode, with even worse performance. Statically compiled code or native code is compiled prior to deployment. A dynamic compilation environment is one in which the compiler can be used during execution. For instance, most Common Lisp systems have a compile function which can compile new functions created during the run. This provides many of the advantages of JIT, but the programmer, rather than the runtime, is in control of what parts of the code are compiled. This can also compile dynamically generated code, which can, in many scenarios, provide substantial performance advantages over statically compiled code, as well as over most JIT systems.
A common goal of using JIT techniques is to reach or surpass the performance of static compilation, while maintaining the advantages of bytecode interpretation: Much of the "heavy lifting" of parsing the original source code and performing basic optimization is often handled at compile time, prior to deployment: compilation from bytecode to machine code is much faster than compiling from source. The deployed bytecode is portable, unlike native code. Since the runtime has control over the compilation, like interpreted bytecode, it can run in a secure sandbox. Compilers from bytecode to machine code are easier to write, because the portable bytecode compiler has already done much of the work.
JIT code generally offers far better performance than interpreters. In addition, it can in some cases offer better performance than static compilation, as many optimizations are only feasible at run-time:
- The compilation can be optimized to the targeted CPU and the operating system model where the application runs. For example JIT can choose SSE2 CPU instructions when it detects that the CPU supports them. To obtain this level of optimization specificity with a static compiler, one must either compile a binary for each intended platform/architecture, or else include multiple versions of portions of the code within a single binary.
- The system is able to collect statistics about how the program is actually running in the environment it is in, and it can rearrange and recompile for optimum performance. However, some static compilers can also take profile information as input.
- The system can do global code optimizations (e.g. inlining of library functions) without losing the advantages of dynamic linking and without the overheads inherent to static compilers and linkers. Specifically, when doing global inline substitutions, a static compiler must insert run-time checks and ensure that a virtual call would occur if the actual class of the object overrides the inlined method (however, this need not be the case for languages employing a static type discipline).
- Although this is possible with statically compiled garbage collected languages, a bytecode system can more easily rearrange memory for better cache utilization.
[edit]Startup delay and optimizations
JIT typically causes a slight delay in initial execution of an application, due to the time taken to load and compile the bytecode. Sometimes this delay is called "startup time delay". In general, the more optimization JIT performs, the better the code it will generate, but the initial delay will also increase. A JIT compiler therefore has to make a trade-off between the compilation time and the quality of the code it hopes to generate. However, it seems that much of the startup time is sometimes due to IO-bound operations rather than JIT compilation (for example, the rt.jar class data file for the Java Virtual Machine is 40 MB and the JVM must seek a lot of data in this huge file).[1]
One possible optimization, used by Sun's HotSpot Java Virtual Machine, is to combine interpretation and JIT compilation. The application code is initially interpreted, but the JVM monitors which sequences of bytecode are frequently executed and translates them to machine code for direct execution on the hardware. For bytecode which is executed only a few times, this saves the compilation time and reduces the initial latency; for frequently executed bytecode, JIT compilation is used to run at high speed, after an initial phase of slow interpretation. Additionally, since a program spends most time executing a minority of its code, the reduced compilation time is significant. Finally, during the initial code interpretation, execution statistics can be collected before compilation, which helps to perform better optimization.[2]
The correct tradeoff can vary due to circumstances. For example, Sun's Java Virtual Machine has two major modes—client and server. In client mode, minimal compilation and optimization is performed, to reduce startup time. In server mode, extensive compilation and optimization is performed, to maximize performance once the application is running by sacrificing startup time. Other Java just-in-time compilers have used a runtime measurement of the number of times a method has executed combined with the bytecode size of a method as a heuristic to decide when to compile.[3] Still another uses the number of times executed combined with the detection of loops.[4] In general, it is much harder to accurately predict which methods to optimize in short-running applications than in long-running ones.[5]
Native Image Generator (Ngen) by Microsoft is another approach at reducing the initial delay.[6] Ngen pre-compiles (or "pre-jits") bytecode in a Common Intermediate Language image into machine native code. As a result, no runtime compilation is needed. .NET framework 2.0 shipped with Visual Studio 2005 runs Ngen on all of the Microsoft library DLLs right after the installation. Pre-jitting provides a way to improve the startup time. However, the quality of code it generates might not be as good as the one that is jitted, for the same reasons why code compiled statically, without profile-guided optimization, cannot be as good as JIT compiled code in the extreme case: the lack of profiling data to drive, for instance, inline caching.[7]
There also exist Java implementations that combine an AOT (ahead-of-time) compiler with either a JIT compiler (Excelsior JET) or interpreter (GNU Compiler for Java.)
[edit]History
The earliest published JIT compiler is generally attributed to work on LISP by McCarthy in 1960.[8] In his seminal paper Recursive functions of symbolic expressions and their computation by machine, Part I, he mentions functions that are translated during runtime, thereby sparing the need to save the compiler output to punch cards.[9] In 1968, Thompson presented a method to automatically compile regular expressions to machine code, which is then executed in order to perform the matching on an input text.[10][8] An influential technique for deriving compiled code from interpretation was pioneered by Mitchell in 1970, which he implemented for the experimental languageLC².[11][8]
Smalltalk pioneered new aspects of JIT compilations. For example, translation to machine code was done on demand, and the result was cached for later use. When memory became sparse, the system would delete some of this code and regenerate it when it was needed again.[12][8] Sun's Self language improved these techniques extensively and was at one point the fastest Smalltalk system in the world; achieving up to half the speed of optimized C[13] but with a fully object-oriented language.
Self was abandoned by Sun, but the research went into the Java language, and currently it is used by most implementations of the Java Virtual Machine, as HotSpotbuilds on, and extensively uses, this research base.
The HP project Dynamo was an experimental JIT compiler where the bytecode format and the machine code format were of the same type; the system turned HPA-8000 bytecode into HPA-8000 machine code. Counterintuitively, this resulted in speed ups, in some cases of 30% since doing this permitted optimizations at the machine code level, for example, inlining code for better cache usage and optimizations of calls to dynamic libraries and many other run-time optimizations which conventional compilers are not able to attempt.[14]
[edit]See also
- Binary translation
- HotSpot
- Common Language Runtime
- Crusoe, a microprocessor that essentially performs just-in-time compilation from x86 code to microcode within the microprocessor
- GNU lightning — A library that generates assembly language code at run-time
- LLVM
- Self-modifying code
[edit]References
- ^ Haase, Chet (May 2007). "Consumer JRE: Leaner, Meaner Java Technology". Sun Microsystems. Retrieved 2007-07-27. "At the OS level, all of these megabytes have to be read from disk, which is a very slow operation. Actually, it's the seek time of the disk that's the killer; reading large files sequentially is relatively fast, but seeking the bits that we actually need is not. So even though we only need a small fraction of the data in these large files for any particular application, the fact that we're seeking all over within the files means that there is plenty of disk activity. "
- ^ The Java HotSpot Performance Engine Architecture
- ^ Schilling, Jonathan L. (February 2003). "The simplest heuristics may be the best in Java JIT compilers". SIGPLAN Notices 38 (2): 36–46. doi:10.1145/772970.772975.
- ^ Toshio Suganuma, Toshiaki Yasue, Motohiro Kawahito, Hideaki Komatsu, Toshio Nakatani, "A dynamic optimization framework for a Java just-in-time compiler",Proceedings of the 16th ACM SIGPLAN conference on Object-oriented programming, systems, languages, and applications (OOPSLA '01), pp. 180-195, October 14–18, 2001.
- ^ Matthew Arnold, Michael Hind, Barbara G. Ryder, "An Empirical Study of Selective Optimization", Proceedings of the 13th International Workshop on Languages and Compilers for Parallel Computing-Revised Papers, pp. 49-67, August 10–12, 2000.
- ^ http://msdn2.microsoft.com/en-us/library/6t9t5wcf(VS.80).aspx
- ^ Matthew R. Arnold, Stephen Fink, David P. Grove, Michael Hind, and Peter F. Sweeney, "A Survey of Adaptive Optimization in Virtual Machines", Proceedings of the IEEE, 92(2), February 2005, pp. 449-466.
- ^ a b c d Aycock, J. (June 2003). "A brief history of just-in-time". ACM Computing Surveys 35 (2): 97–113. doi:10.1145/857076.857077. Retrieved 2010-05-24.
- ^ McCarthy, J. (April 1960). "Recursive functions of symbolic expressions and their computation by machine, Part I". Communications of the ACM 3 (4): 184–195.doi:10.1145/367177.367199. Retrieved 24 May 2010.
- ^ Thompson, K. (June 1968). "Programming Techniques: Regular expression search algorithm". Communications of the ACM 11 (6): 419–422.doi:10.1145/363347.363387. Retrieved 2010-05-24.
- ^ Mitchell, J.G. (1970), The design and construction of flexible and efficient interactive programming systems
- ^ Deutsch, L.P.; Schiffman, A.M. (1984), "Efficient implementation of the Smalltalk-80 system", POPL '84: Proceedings of the 11th ACM SIGACT-SIGPLAN Symposium on Principles of Programming Languages: 297–302, doi:10.1145/800017.800542
- ^ http://research.sun.com/jtech/pubs/97-pep.ps
- ^ Ars Technica on HP's Dynamo
피드 구독하기:
글 (Atom)